Table of Contents
Outliers and missing values are common challenges in data analysis and modeling. They can significantly affect the accuracy and reliability of analytical results. Therefore, it is crucial to address these issues appropriately. However, a question often arises: Which should be addressed first, outlier treatment or missing value imputation? In this article, we will explore this topic in detail and provide insights to help you make an informed decision.
Data quality plays a vital role in deriving meaningful insights from any analysis. Outliers and missing values are two types of data irregularities that require attention. Outliers are data points that deviate significantly from the majority of the data, while missing values occur when data for a particular variable is absent or unknown.
Understanding Outliers and Missing Values
What are outliers?
Outliers are extreme observations that lie far away from the central tendency of the data. They can arise due to various reasons, such as measurement errors, data entry mistakes, or genuine anomalies in the data generation process. Outliers can distort statistical measures and affect the interpretation of data.
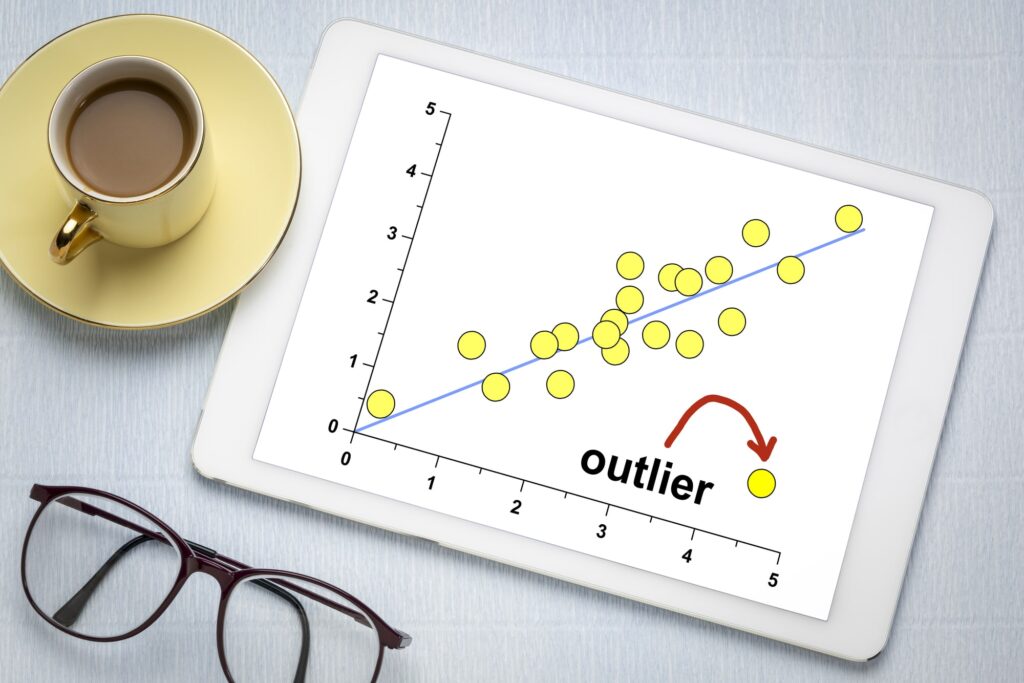
What are missing values?
Missing values refer to the absence of data for one or more variables in a dataset. They can occur for several reasons, including non-response by survey participants, data corruption, or accidental omission during data collection or recording. Missing values can lead to biased analysis and inaccurate conclusions if not handled properly.

Importance of handling outliers and missing values
Handling outliers and missing values is crucial for several reasons. Firstly, outliers can affect the distributional properties of data, making it necessary to identify and treat them appropriately. Secondly, missing values can introduce bias and impact the accuracy of statistical models. Addressing outliers and missing values is essential to ensure the reliability of data analysis results and the validity of any subsequent conclusions.
Outlier Treatment Techniques
Identifying outliers
Before addressing outliers, it is essential to identify them. Various statistical methods and graphical techniques can be employed for outlier detection, such as box plots, z-scores, and modified z-scores. These methods help to determine which data points are significantly different from the rest.
Handling outliers
Once outliers are identified, several techniques can be employed to handle them effectively.
Removing outliers
In certain cases, outliers can be safely removed from the dataset if they are deemed as erroneous or irrelevant to the analysis. However, caution must be exercised when removing outliers, as it can lead to information loss and potentially impact the analysis.
Transforming outliers
Another approach to handling outliers is to transform the data. This can involve using mathematical functions like logarithmic or square root transformations to reduce the
impact of outliers. Transforming the data can help normalize the distribution and make it more suitable for analysis.
Replacing outliers
Alternatively, outliers can be replaced with more appropriate values. This can involve imputing values based on statistical measures such as the mean, median, or mode of the variable. Replacing outliers should be done carefully, considering the context and characteristics of the data.
Missing Value Imputation Methods
Identifying missing values
Similar to outliers, it is crucial to identify missing values before applying imputation techniques. Various approaches, such as summary statistics or visualization techniques, can be used to detect missing values in the dataset.
Handling missing values
There are several methods available for handling missing values, each with its advantages and limitations.
Deleting missing values
In certain cases, if the proportion of missing values is relatively small and they are missing completely at random (MCAR), deleting the corresponding records can be a valid approach. However, caution must be exercised to ensure that valuable information is not lost in the process.
Mean imputation
Mean imputation involves replacing missing values with the mean value of the variable. This method assumes that the missing values have a similar distribution as the observed values. While simple to implement, mean imputation may not be appropriate for variables with skewed distributions.
Median imputation
Similar to mean imputation, median imputation replaces missing values with the median value of the variable. Median imputation is robust to outliers and can be preferred when dealing with skewed data.
Mode imputation
Mode imputation replaces missing values with the mode (most frequent value) of the variable. This method is commonly used for categorical variables or variables with a limited number of distinct values.
Regression imputation
Regression imputation involves predicting missing values based on the relationship between the variable with missing values and other variables. This method can be effective when there is a significant correlation between the variables.
Deciding the Order: Outlier Treatment or Missing Value Imputation?
When deciding the order of outlier treatment and missing value imputation, several factors should be considered.
Considerations for order of treatment
The decision of which to address first depends on the nature of the data and the specific analysis objectives. If outliers are severe and have a substantial impact on the data distribution, addressing them first might be beneficial. On the other hand, if missing values are prevalent and might affect the subsequent imputation process, dealing with missing values first can be more appropriate.
Impact on data analysis and modeling
The order of outlier treatment and missing value imputation can influence the results of data analysis and modeling. Addressing outliers first can lead to a more accurate representation of the data distribution, which can impact subsequent statistical tests and model performance. Similarly, handling missing values before modeling can help avoid bias in parameter estimates and improve the model’s predictive power.
General guidelines
While there is no one-size-fits-all approach, some general guidelines can be followed. If outliers are gross and easily identifiable, addressing them first can help in creating a cleaner dataset. However, if the missing values are extensive and might affect subsequent analyses, handling them first is advisable. It is crucial to consider the specific characteristics of the dataset and the analysis goals when making a decision.
6. Conclusion
In conclusion, both outlier treatment and missing value imputation are essential steps in ensuring data quality. The decision of which to address first depends on various factors, including the nature of the data, the severity of outliers, and the prevalence of missing values. By carefully considering these factors and following general guidelines, analysts can make informed decisions and obtain reliable analytical results.
FAQs
- Can outliers and missing values occur together in a dataset?
Yes, it is possible to have both outliers and missing values in the same dataset. It is important to address each issue separately to ensure data quality. - What is the impact of outliers on statistical analysis?
Outliers can distort statistical measures, affect the distributional properties of data, and lead to inaccurate conclusions. Handling outliers is crucial for reliable analysis. - Are there any automated tools available for outlier detection and missing value imputation?
Yes, several software packages and programming libraries provide functions and algorithms for outlier detection and missing value imputation. These tools can assist analysts in handling data irregularities efficiently. - Is it always necessary to remove outliers from the dataset?
No, removing outliers is not always necessary. It depends on the specific analysis goals and the nature of the outliers. Sometimes, outliers can provide valuable insights or indicate interesting patterns in the data. - Can missing value imputation introduce bias in the analysis?
Yes, if missing value imputation is not performed carefully, it can introduce bias in the analysis. It is essential to choose appropriate imputation methods based on the characteristics of the data.