
Optimizing Inference for Autoregressive Decoding

Introduction
Large language models (LLMs) like GPT, PaLM, and LLaMA rely on transformer architectures to generate human-like text. However, autoregressive decoding—where the model generates tokens one at a time—poses significant computational challenges. Each new token requires reprocessing all previous tokens, leading to redundant calculations and slow inference. To address this, the Key-Value (KV) Cache has become a critical optimization technique. This article explores the mechanics, benefits, and challenges of KV caching, along with its role in accelerating modern LLMs.
What is KV Cache?
The KV Cache is a memory-efficient technique used during the inference phase of transformer-based models. It stores intermediate computations of key and value vectors from the self-attention layers, avoiding redundant recalculations for previously processed tokens. By caching these vectors, the model reuses them for subsequent token generations, drastically reducing computational overhead.
Why is KV Cache Important?
In autoregressive models like GPT, generating a sequence of length N requires O(N2) computations for self-attention. Without caching, each new token reprocesses all prior tokens, leading to inefficiency. KV caching reduces this complexity to O(N) for incremental decoding, making long-sequence generation feasible.
How KV Cache Works
1. Self-Attention Recap
In transformers, the self-attention mechanism computes three vectors for each token:
- Query (Q): Determines relevance of other tokens to the current one.
- Key (K): Used to compute attention weights.
- Value (V): Provides contextual information for the output.
The attention output is calculated as:

2. Caching Keys and Values
During autoregressive decoding:
- First Token: Compute and store the keys (K) and values (VV for all previous tokens.
- Subsequent Tokens: Compute Q for the new token, but reuse cached K and V from earlier steps.
- Cache Update: Append the new token’s K and V to the cache for future steps.
This avoids recomputing K and V for the entire sequence at every step.
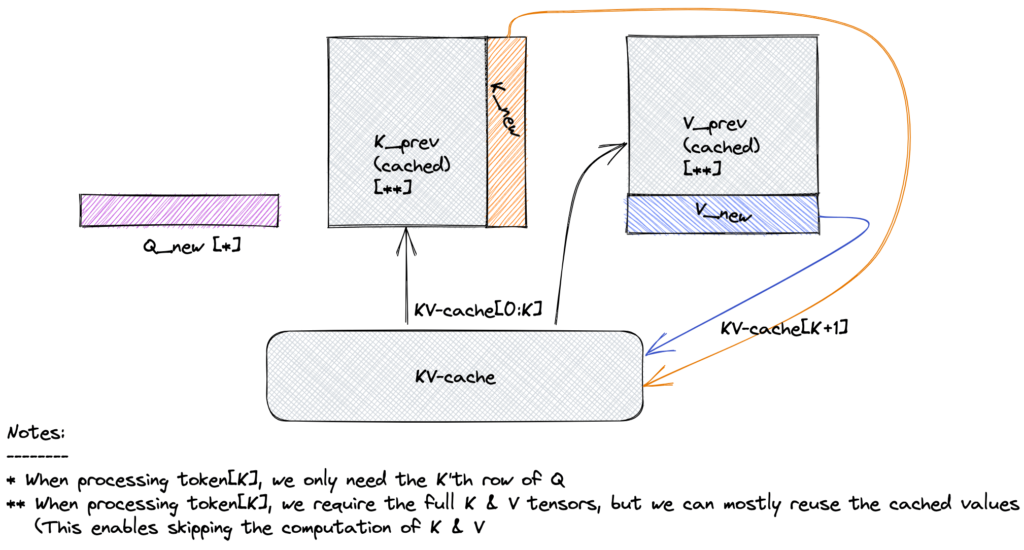
Figure: KV Cache avoids recomputing keys/values for prior tokens during autoregressive decoding.
Benefits of KV Cache
1. Faster Inference
- Reduces redundant computations, speeding up token generation by 3–10x compared to non-cached inference.
- Critical for real-time applications like chatbots or voice assistants.
2. Lower Computational Complexity
- Reduces the per-token computational cost from O(N2) to O(N)for sequences of length N.
3. Memory Bandwidth Efficiency
- Minimizes data transfer between GPU memory and compute units by reusing cached vectors.
4. Scalability
- Enables efficient generation of long sequences (e.g., documents, code) without quadratic slowdown.
Challenges and Limitations
1. Memory Overhead
- The cache grows linearly with sequence length, consuming significant GPU memory.
- Example: A 13B-parameter model with 40 layers and 5120-dimensional embeddings requires ~40 MB per token.
- For 2048-token sequences, this exceeds 80 GB of memory.
2. Memory Bandwidth Bottlenecks
- Frequent reads/writes to the cache can strain GPU memory bandwidth, limiting speed gains.
3. Complexity in Dynamic Workloads
- Managing the cache for batched inference (e.g., variable-length sequences) adds engineering complexity.
4. Limited Parallelism
- Autoregressive decoding is inherently sequential, though techniques like speculative decoding mitigate this.
Implementing KV Cache: Best Practices
1. Memory Management
- Windowed Attention: Limit cache size by discarding tokens beyond a fixed window (e.g., 4096 tokens).
- Paged Attention: Allocate cache in non-contiguous memory blocks (used in vLLM).
2. Hardware Optimization
- Use GPUs with high memory bandwidth (e.g., NVIDIA A100, H100) to handle cache operations efficiently.
3. Framework Support
- Leverage built-in KV caching in libraries like:
- Hugging Face Transformers (
use_cache=True). - NVIDIA’s FasterTransformer.
- vLLM (optimized for high-throughput serving).
- Hugging Face Transformers (
4. Quantization
- Compress cached K and V vectors using 8-bit or 4-bit quantization to reduce memory usage.
Use Cases
1. Text Generation
- Chatbots (e.g., ChatGPT), story writing, and code completion.
2. Machine Translation
- Efficiently generate long translated sequences.
3. Real-Time Applications
- Voice assistants requiring low-latency responses.
4. Long-Context Tasks
- Summarization, question answering over lengthy documents.
KV Cache vs. Other Optimizations
| Technique | Purpose | Impact on Inference |
|---|---|---|
| KV Cache | Reuse past computations | Reduces FLOPs, speeds up decoding |
| Quantization | Reduce precision of weights | Lowers memory usage |
| Pruning | Remove unimportant weights | Reduces model size |
| FlashAttention | Optimize attention computation | Lowers memory bandwidth usage |
Future Directions
- Sparse KV Cache: Retain only top-k relevant tokens in the cache.
- Distributed Caching: Split cache across multiple GPUs for ultra-long sequences.
- Compression Algorithms: Apply lossy/lossless compression to cached vectors.
- Hardware Innovations: GPUs/TPUs with dedicated cache management units.
Conclusion
The KV Cache is a cornerstone of efficient inference in modern LLMs, enabling faster, scalable, and cost-effective text generation. While memory constraints remain a challenge, advancements in quantization, attention algorithms, and hardware continue to push the boundaries of what’s possible. For developers and researchers working with transformers, mastering KV caching is essential to unlocking the full potential of autoregressive models in production environments. As LLMs grow larger and more ubiquitous, optimizing their inference through techniques like KV caching will remain a key focus in AI innovation.


