
ARIMA, which stands for AutoRegressive Integrated Moving Average, is a widely-used statistical method for time series forecasting. It combines autoregressive, differencing, and moving average components to model data patterns.

What is ARIMA?
ARIMA is a mathematical model that describes a time series as a combination of autoregressive (AR), differencing (I), and moving average (MA) components. These components are denoted by the parameters p, d, and q, respectively.
Components of ARIMA
- Autoregressive Component (AR): This component models the relationship between an observation and several lagged observations.
- Integrated Component (I): This component represents the number of differences needed to make the time series data stationary.
- Moving Average Component (MA): This component accounts for the error term as a linear combination of previous error terms.
By understanding and appropriately selecting these components, one can create an effective ARIMA model tailored to their specific dataset.
Autoregressive (AR) Component
The autoregressive component of an ARIMA model focuses on modeling the relationship between an observation and a lagged version of itself. This is expressed mathematically as:
[X_t = \phi_1 X_{t-1} + \phi_2 X_{t-2} + … + \phi_p X_{t-p} + \epsilon_t]Here, (\phi_1, \phi_2, …, \phi_p) are the autoregressive parameters, (X_t) represents the current observation, and (\epsilon_t) is the error term.
Explanation of Autoregressive Component
The autoregressive component essentially looks at how the previous observations contribute to the current value. For instance, in a stock market context, it would analyze how past prices affect the present price.
Selecting the Order of AR (p)
Determining the order of the autoregressive component ((p)) involves identifying how many lagged observations are significant. This can be accomplished using techniques like the partial autocorrelation function (PACF) plot.
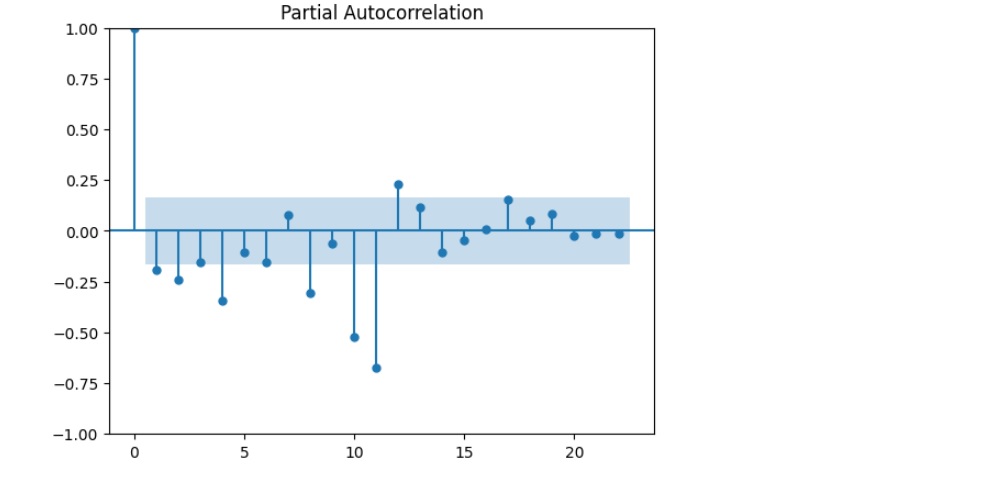
By choosing the right order of AR, you refine the model’s ability to capture dependencies from previous time points.
Integrated (I) Component
The integrated component of an ARIMA model focuses on differencing the time series data to make it stationary. Stationarity is crucial for accurate modeling as it ensures that the statistical properties of the data remain constant over time.
Understanding Integrated Component
Differencing involves subtracting the current observation from the previous observation. The number of differences required to achieve stationarity is denoted by the parameter ‘d’. Mathematically, it can be represented as:
[Y_t = (1 – B)^d X_t]Where (Y_t) represents the differenced series, (X_t) is the original series, and ‘B’ is the backshift operator.
Selecting the Order of Integration (d)
Choosing the appropriate order of integration ((d)) is a crucial step in ARIMA modeling. It determines how many times differencing needs to be applied to achieve stationarity. This can be determined through visual inspection of the data and using statistical tests like the Augmented Dickey-Fuller test.
If the data appears to have a trend or seasonality, a higher order of integration may be required. It’s important to strike a balance – too much differencing can lead to information loss, while too little may result in a non-stationary model.
Moving Average (MA) Component
The moving average component of an ARIMA model focuses on modeling the error term as a linear combination of previous error terms. This component helps capture short-term fluctuations in the data.
Demystifying Moving Average Component
Mathematically, the moving average component is represented as:
[X_t = \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + … + \theta_q \epsilon_{t-q}]Where (\epsilon_t) represents the current error term, and (\theta_1, \theta_2, …, \theta_q) are the moving average parameters.
The moving average component helps in filtering out short-term noise and isolating the underlying patterns in the data.
Selecting the Order of MA (q)
Determining the order of the moving average component ((q)) is a crucial step in building an effective ARIMA model. It signifies how many lagged error terms to include in the model.
This can be done through methods like the autocorrelation function (ACF) and partial autocorrelation function (PACF) plots. These plots provide insights into the lag values that significantly influence the current observation.

By carefully selecting the order of the moving average component, you can enhance the model’s ability to capture short-term fluctuations.
Stationarity and Differencing
Achieving stationarity is a crucial step in time series analysis. A stationary time series has constant statistical properties over time, which simplifies modeling.
The Concept of Stationarity
A time series is considered stationary if its mean, variance, and autocovariance remain constant over time. Stationarity ensures that the underlying patterns in the data are not changing.
Applying Differencing for Stationarity
Differencing is a technique used to remove trends or seasonality from a time series. By subtracting the previous observation from the current one, you can eliminate any linear trends.
Identifying Seasonality
Seasonality refers to recurring patterns that occur at regular intervals within a time series. Recognizing these patterns is crucial for accurate forecasting.
Recognizing Seasonal Patterns
Seasonal patterns can be observed in various domains, such as retail sales (spikes during holidays) or weather data (temperature fluctuations across seasons).
Seasonal Differencing in ARIMA
In cases where seasonality is present, seasonal differencing can be applied in addition to regular differencing. This involves subtracting the observation from the same season in the previous year.
Choosing the Right Order
Selecting the right order of the ARIMA model is a critical step in building an accurate forecasting model. The AIC and BIC criteria are commonly used methods for model selection.
AIC and BIC Criteria
The Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) are statistical measures used to compare the goodness of fit of different models. Lower values indicate better-fitting models.
Grid Search Method
Grid search involves systematically testing a range of hyperparameters to identify the combination that produces the best model performance. This method is particularly useful for automating model selection.
Fitting the ARIMA Model
Once the components and their respective orders are determined, the ARIMA model can be fitted to the data using various software packages.
Implementing the ARIMA Model in Python
Python offers libraries like statsmodels that provide functionalities for ARIMA modeling. This includes functions for model fitting, forecasting, and model evaluation.
Evaluating Model Fit
Model fit can be assessed using statistical measures like Mean Absolute Error (MAE), Mean Squared Error (MSE), and Root Mean Squared Error (RMSE). Additionally, visual inspection of the residuals can provide insights into model performance.
Forecasting with ARIMA
After fitting the ARIMA model, it can be used to make future predictions based on the historical data.
Making Future Predictions
Using the model, you can forecast future data points. This is valuable for planning and decision-making in various domains.
Visualizing Forecasted Data
Visualizing the forecasted data alongside the actual data allows for a clear understanding of the model’s predictive capabilities. This can help identify any areas where the model may need further refinement.
Model Validation
Validating the ARIMA model is crucial to ensure its accuracy and reliability in making forecasts.
Out-of-Sample Testing
Out-of-sample testing involves evaluating the model’s performance on data that it hasn’t seen before. This provides a realistic assessment of how the model will perform in real-world scenarios.
Measuring Forecast Accuracy
Forecast accuracy can be assessed using metrics like Mean Absolute Percentage Error (MAPE) and Forecast Bias. These metrics quantify the level of accuracy achieved by the model.
Handling Anomalies and Outliers
Anomalies and outliers in the data can significantly impact the performance of an ARIMA model.
Impact on ARIMA Model
Outliers can introduce noise and lead to inaccurate predictions. It’s essential to identify and handle them appropriately.
Strategies for Outlier Handling
Techniques like winsorization, data transformation, or using robust models can be employed to mitigate the effects of outliers on the model.
Fine-Tuning ARIMA Models
Fine-tuning the ARIMA model involves making adjustments to improve its performance and accuracy.
Model Refinement Techniques
Techniques like seasonal decomposition, parameter optimization, and incorporating exogenous variables can enhance the model’s forecasting capabilities.
Adjusting Parameters for Improved Performance
Iteratively adjusting the AR, I, and MA orders, as well as considering seasonal components, can lead to a more accurate model.
Common Pitfalls and Challenges
While ARIMA is a powerful tool, there are common pitfalls that practitioners should be aware of.
Overfitting and Underfitting
Overfitting occurs when the model is too complex and captures noise in the data. Underfitting, on the other hand, happens when the model is too simple to capture the underlying patterns.
Dealing with Noisy Data
Noisy data can obscure meaningful patterns. Data cleaning and preprocessing techniques are crucial for effective modeling.
Conclusion
In conclusion, understanding the various parameters of an ARIMA model is essential for accurate time series forecasting. By breaking down the components and following a systematic approach, you can effectively apply ARIMA to your own datasets.
FAQs
Can ARIMA handle seasonal data patterns?
- Yes, ARIMA can be extended to incorporate seasonal components through seasonal differencing.
How do I know if my time series data needs differencing?
- You can perform a visual inspection of the data plot to check for any obvious trends or seasonality. Additionally, statistical tests like the Augmented Dickey-Fuller test can be used.
What is the significance of the AIC and BIC criteria in ARIMA model selection?
- The Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC) are used to compare the goodness of fit of different models. Lower values indicate better-fitting models.
How can outliers impact the performance of an ARIMA model?
- Outliers can distort the modeling process, leading to inaccurate predictions. It’s important to identify and handle outliers appropriately.
Are there automated tools available for ARIMA modeling?
- Yes, there are various libraries and software packages, such as Python’s
statsmodelsand R’sforecastpackage, that provide functionalities for ARIMA modeling.
***
Machine Learning books from this Author:




